
汤姆和杰瑞,第70集(译者注:直到暑假去了上海Disney,我才知道它和兔八哥、啄木鸟伍迪都和迪士尼木有关系=-=)--按键猫(1952)
作者 | Denis Vorotyntsev
译者 | 呀啦呼
编辑 | 唐里
任何行业,挖掘数据的原因,无外乎是为了利润。而ML和data viz能帮助公司的决策者低成本的抽丝剥茧降维分析自己的商业需求。
我在多个机器学习竞赛中为了融合主要的模型使用了AutoML,并且我参与了两个AutoML的竞赛。我认为AutoML作为使建模过程自动化的一种想法非常出色,但是该领域被过度炒作(overhyped)。一些关键概念,例如特征工程(features engineering)或用于参数优化的元学习(meta-learning),将释放其潜力,但就目前而言,将封装的AutoML作为工具只是浪费金钱。
以下所有文本均与表格数据有关。
一、AutoML是嘛玩意?Data Science projects数据科学项目任何数据科学项目都包含几个基本步骤:从业务角度提出问题(选择成功的任务和度量标准),收集数据(收集,清理,探索),建立模型和评估其性能,在生产环境中部署模型并观察模型在生产中的表现。
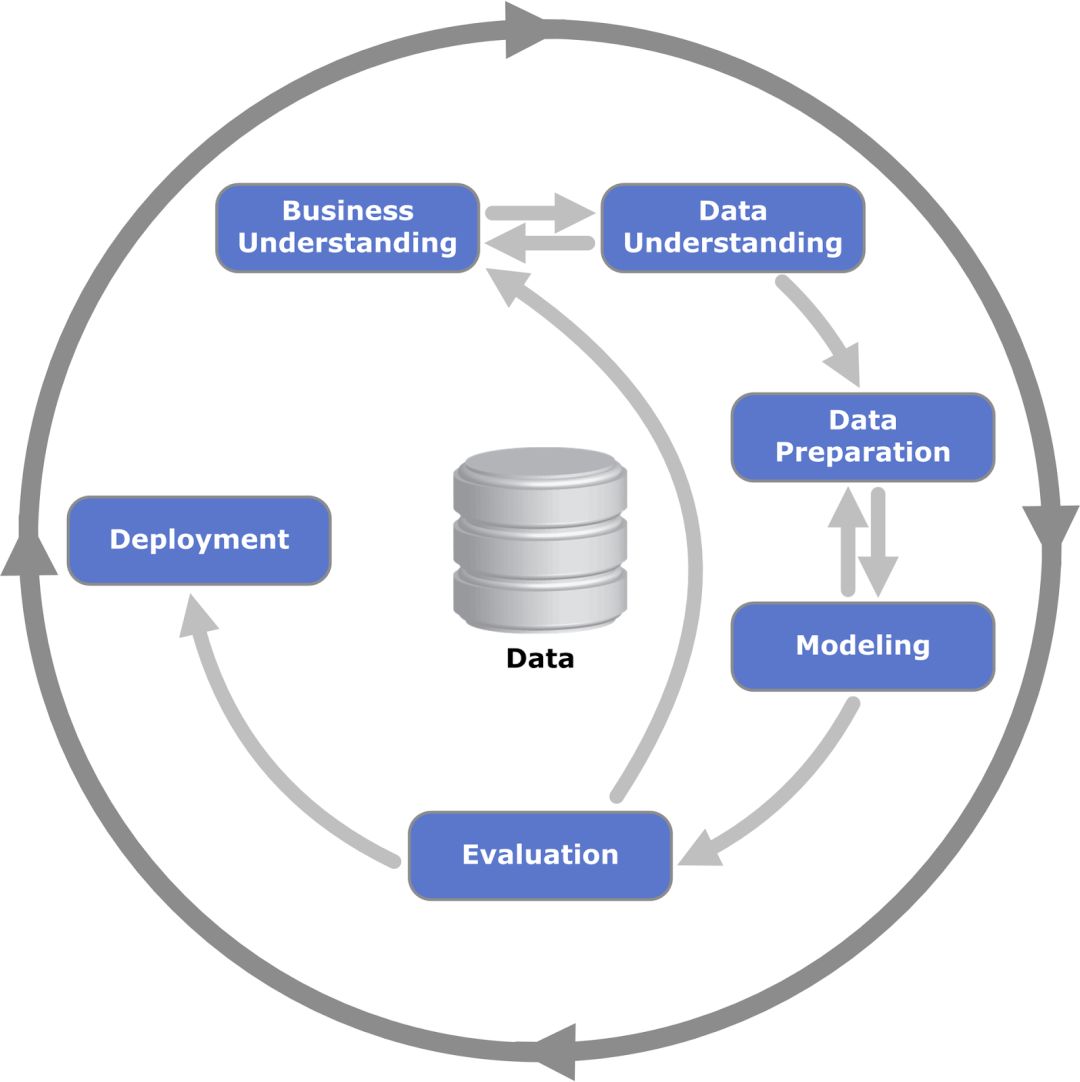
跨行业的数据挖掘标准流程过程的每个部分对于项目的成功都至关重要。但是,从机器学习的最擅长角度来看,建模部分至关重要,因为完善的ML模型可能会为公司带来很多价值。
在建模阶段,数据科学家正在解决优化任务:使用给定的数据集,目标-最大化所选指标。这个过程很复杂,它需要不同类型的技能:1. 特征工程有时被视为艺术,而非科学(译者:我猜作者表达的是很多时候我们需要直觉或者经验总结,但是我不同意归为艺术);2. 参数优化需要对算法和核心ML概念有深入的了解;3. 需要软件工程技能(码畜们存在的意义)来让输出的代码易于理解、部署。这就是为啥我们需要AutoML。

ML建模和软件工程一样,像是艺术和科学的结合体AutoMLAutoML的输入是数据和任务(classification, regression, recommendations等),输出-生产就绪模型,该模型能够预测隐藏的数据。数据驱动管道中的每个决定都是一个参数(译者:闹不懂作者的意思,有点玄学)。AutoML的基本想法是找到这样的参数,这些参数可以在合理的时间内给出良好的分数。AutoML选择了一种预处理数据的策略:如何处理不平衡的数据;如何处理不平衡的数据;如何填充缺失值;outlier的删除,替换或保留;如何编码类别和多类别列;如何避免目标泄漏;如何防止内存错误;等等。
AutoML生成很多新的特征并且选择当中有意义的;
AutoML自动选择适合的模型(Linear models, K-Nearest Neighbors, Gradient Boosting, Neural Nets, 等等);
AutoML为选择的模型进行参数优化(比如tree-based的模型有多少子树数量和子采样数, 神经网络的learning rate和epochs数量
AutoML建立了一个模型集成(译者:大杂烩,嘛都有)来尽可能的让模型分数更高。
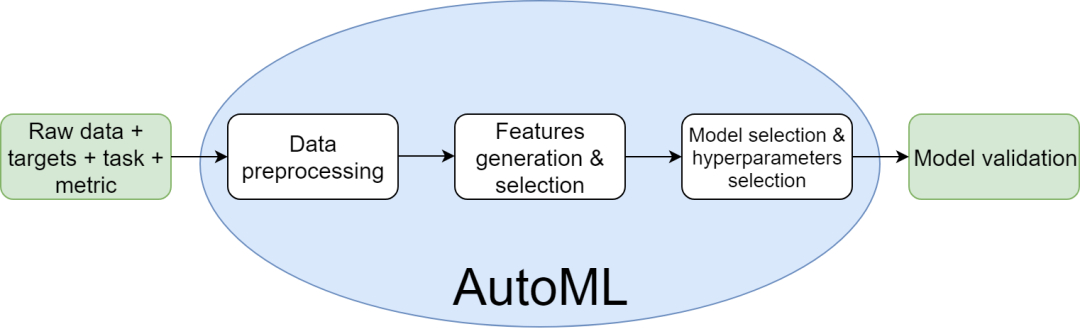
二、AutoML的动机AutoML将填补数据科学市场中供需之间的缺口如今,越来越多的公司要么开始收集数据,要么想变现已收集数据的潜力:他们希望从中获得价值(译者:作者应该表达的是商业价值)。可是没有太多具有适当背景的数据科学家可以满足需求,因此巨大的缺口出现了。AutoML有可能会填补上。但是这样的封装解决方案能给公司带来任何价值吗?我认为答案是“否”。这些公司需要一个过程,但是AutoML只是一个工具。先进的工具无法弥补战略上的不足。在开始使用AutoML之前,请考虑先找咨询公司来个项目(译者:瓜娃子作者是咨询公司的托吧),这可能首先帮助您制定数据科学策略。大多数AutoML解决方案提供商也提供咨询服务并不是巧合。
看起来不像是一个完美计划,对吧(“South Park”, s2e17)AutoML将会大幅节省数据科学团队的时间根据2018 Kaggle ML and Data Science Survey, 一个数据可选的项目15-26%的时间花费在建模或者模型选择。无论是考虑“员工工时”还是消耗的计算时间,这都是一项艰巨的任务。如果目标或数据发生更改(例如添加新特征),之前的过程就会被重复。AutoML可以帮助公司内的数据科学家节省时间,并将其更多地花费在更重要的事情上(例如在椅子上击剑)。
而我们在开始使用AutoML之前仅仅需要几行代码。但是,如果数据科学团队的建模部分不是最关键的任务,则你的公司流程中显然存在问题。通常,即使模型性能的小幅提高也可能为公司赚取大量金钱,在这种情况下,建模时间是值得开销的时间:

让你的数据科学团队给日常任务编写脚本而不是使用封装的解决方案是一个好主意。 我为日常任务的自动化编写了一些脚本:自动特征生成,特征选择,模型训练和参数tuning,而这些我现在每天都在使用。AutoML比普通的数据科学家更厉害除了"An Open Source AutoML Benchmark”, 我们没有任何有用的“AutoML vs 人类”的benchmarks。该论文的作者在2019年7月1日发布了几个AutoML库与优化后的Random Forest性能的比较结果。
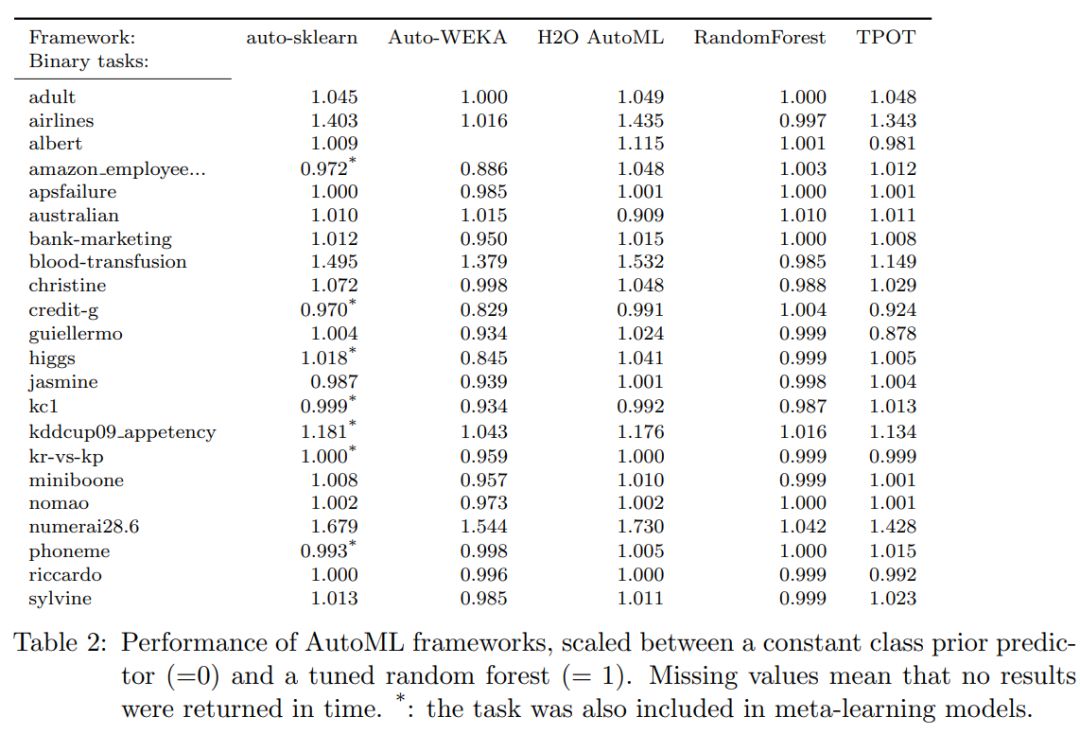
我挺好奇的,然后来做我自己的benchmarks.我在三个数据集( credit, KDD Upselling, 和 mortgages)上比较了我的模型和AutoML的性能。我把数据集分为训练集(按目标分层随机分配了60%的数据)和测试集(剩余40%).我的基准解决方案相对简单。 我没有深入研究数据,也没有创建任何高级特征:5-StratifiedKFold;
用于分类列的Catboost编码器,如果您对CatBoost编码器不熟悉,请查看我之前的文章:Benchmarking Categorical Encoders;
数字列对的数学运算(+-* /)。 新特征数量的上限:500;
模型: 默认参数的LightGBM;
混合(OOF ranked predictions)
我用了两个AutoML的库: H2O 和 TPOT。我分阶段、次数训练了这俩宝贝:从15分钟到6小时。使用以下指标,我得到了令人惊讶的结果:
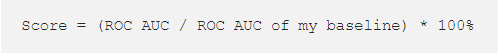
首先,在几乎所有情况下,我的baseline都超过了AutoML。 我有点难过,因为我计划在办公室里放松一下,而AutoML会做所有劳累的工作,但是无所谓咯 ?~~
其次,AutoML的得分并没有随着时间的推移而提高,这意味着我们等待多长时间都没有关系:它在15分钟内和6小时内的得分一样低。AutoML与高分无关。
三、总结如果你的公司想第一次使用其数据,整个咨询顾问先。
你应该让你的工作尽量的自动化。。。
。。。可是封装的解决方案得分很低,看起来并不像是正确的选择。
PS: 引擎并不代表一辆完整的车
在本文中,我谈论的是工具,但是请记住,建模部分只是整个数据科学项目管道的一部分,这一点很重要。 我喜欢将项目比作汽车。 这样,建模(机器学习模型)的输出就是一个引擎。毫无疑问,发动机是必不可少的,但它并不是整车。 你可能需要花费大量时间来设计令人难以置信,周到和复杂的特征,选择神经网络的体系结构或调整Random Forest的参数,从而创建强大的引擎。 但是,如果你没有注意汽车的其他部分,则所有工作可能都没有用。该模型本身可以显示很高的分数,但是由于你解决了错误的问题(业务理解)或数据有偏见,并且必须对其进行重新训练(数据探索)或由于模型过于复杂,因此使用该模型不会被部署。最后,你可能会发现自己很傻:在经过数天或数周的艰苦建模工作后,你驾驶的是一辆装有跑车发动机的慢速自行车。工具必不可少; 策略才是至关重要。

本文编译自技术博客 https://towardsdatascience.com/automl-is-overhyped-1b5511ded65f, 雷锋字幕组编译。



点击“阅读原文”查看 Github项目推荐 | AutoML与轻量模型列表


